

この記事を読むのに必要な時間は約 20 分 17 秒 です。
文字で指示するだけで画像を一から作ることができる 画像生成AI はご存じですか。
生成系AIの中でもとりわけ画像生成の分野は 2022年から急激に製品・サービスが増え、ものすごいスピードで日々新しい機能や製品がリリースされ続けています。
この記事を書いている最中にも新しいサービスが出ているため、ついていくのが難しい分野です。
そのため、現時点での情報であることをご承知ください。
それだけ注目されている分野であり、私自身も非常にワクワクする分野でもあります。
現在画像生成AIの界隈で特に注目されているのが、
- Dall-E2(ダリツー)
- Midjourney(ミッドジャーニー)
- Stable Diffusion(スティーブルディフュージョン)
です。
特に 、Stable Diffusion は GPU を搭載している端末であれば、無料で無制限に実行することができます。
今回はその Stable Diffusion をローカルにインストールして使う方法を解説します。
ちなみにわたしは、資料作成時に「Midjourney」 をメインで使うので「Stable Diffusion」はお試しで触ってみよう程度でした。
しかし、今ではメインツールになっています。
かなり夢中です。
NVIDIA GPU が必要
ローカルで実行する場合は、NVIDIA GPU が必要になります。設定を変えることで CPUでも動作しますが、大幅に時間がかかるのと生成する画像のクオリティーが下がるためお勧めできません。
以前は、Google Colaboratory で動かすことができたみたいですが、今は警告が表示されるためおすすめしないです。
Stable Diffusion とはなに
Stable Diffusionは、Stability AI社からオープンソースとして公開されている画像生成系AIです。
オープンソースなので様々な人がカスタマイズして開発することができ、派生形のサービスもいくつか出始めています。
今回は、通常 CUIで操作しなければならない Stable Diffusion を GUI で操作できるようにするツール、 WebUI をインストールして使います。
WebUI はいくつかあるのですが、いま一番利用されている「Automatic1111」さんが開発した 「Stable Diffusion Automatic1111 WebUI」を利用して解説します。
Stable Diffusion の特徴
ローカルで無制限(無償)で利用可能
Stable Diffusion の特徴は何といっても、オープンソースであることでローカルにインストールすれば無制限に動かすことができます。
画像の生成モデルが豊富
生成する画像のタッチを決めるモデルを自分でダウンロードし切り替えることができるのも魅力です。アニメのような画像や絵画のようなタッチ、まるで写真のような画像もモデルの切り替えで簡単に作成することができます。
そのモデルも日々新しいものが公開され、驚くような進化をしています。
ツールやモデルの拡張機能が豊富
拡張機能が潤沢で、人物のポーズや表情など画像をよりリアルに希望通りにするための拡張機能があります。
他に注目している画像生成AI
モデルを切り替えることができることでアドバンテージがある Stable Diffusion に対して、Webサービスで同じことができるものとして、「Leonardo.Ai」 というサービスがあります。
登録制になりますが無償枠も潤沢にあるため、筆者も今後注目しているサービスの一つです。
Stable Diffusion WebUI をインストールする
実行に必要なもの
Stable Diffusion WebUI は、Pythonで動作するためあらかじめインストールする必要があります。
そのため、実行環境に Python が必要なのと、NVIDIA GPU上で動作するため、NVIDIA のグラフィックボードが必要になります。
- Python 3.10.6
- git
Python のバージョンは、3.10.6 指定で

わたしの実行環境
この記事を書く際に使用したPCは、Surface Laptop Studio という、NVIDIA® GeForce RTX™ 3050 Ti laptop GPU(4GB GDDR6 GPU メモリ) 搭載のノートPCを利用しています。
結論から申し上げると、起動パラメタを変更することでこのスペックでも動作することを確認しています。
他の方の動作推奨だと、12GBのNVIDIA GPU が必要との記事が多いなかで、公式では、推奨スペックの記載はないですが、4GB のビデオカードはサポートとの記載があるため動作するか不安でした。
もちろん負荷が高い処理の場合はメモリが少ないことで動作が難しい場合があるため、GPUのスペックは高いに越したことはないです。
Surface Laptop Studio
スタイリッシュなノートPCで、画面は 2400x1600 Pixels の高精彩で Intel Core i7 の11世代 -11370H プロセッサー、32GB (LPDDR4x) RAM 、NVIDIARTX3050Ti Laptop GPU 搭載で、画像処理はもちろん動画処理、そしてもちろん主流のディープラーニングフレームワークを利用したプログラミングまでもできる。
このデザインに惚れて買っちゃいました。いまは何も不満もなく日々の作業の相棒として活躍しています。
インストール手順
インストール手順は3つだけです。
ただし、いろいろとはまりポイントがあるのであらかじめ説明していきます。
step
1Stable Diffusion WebUI をダウンロードする
step
2起動ファイルを修正する
step
3起動ファイルを実行する
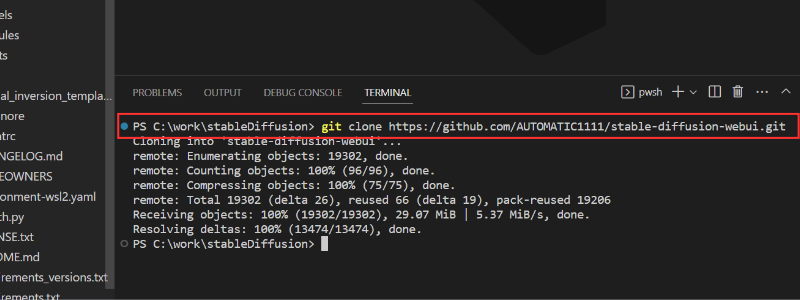
Step1 Stable Diffusion WebUI を github からダウンロード(クローン)する
Stable Diffusion WebUI はGitHub上で公開されています。
ローカルにクローンしてきて利用することになります。
お好みのディレクトリに移動して、コンソールを開き以下コマンドを実行してください。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git数秒でダウンロードすることができます。
Step2 起動ファイルを修正する
この作業は必要がある場合のみ行います。
それぞれ、条件に当てはまる人は実施してください。
- Python を複数インストールしている人
- ローカル環境(GPU)が非力または、解像度が高い画像を作りたい人
変更するファイルは、以下の2つのファイルとなります。
- webui.bat
- webui-user.bat
変更する際は、元ファイルをバックアップ(コピー)してから実施することをお勧めします。
1. Python を複数インストールしている人
Stable Diffusion WebUI は、インストール時に内部でローカル環境に Python 仮想環境を構築します。
その際に利用する起動スクリプトで Python コマンドを実行するのですが、Python を複数インストールしている人は指定したバージョンで動作しない場合があります。
36行目
%PYTHON_FULLNAME% -m venv "%VENV_DIR%" >tmp/stdout.txt 2>tmp/stderr.txtこのパスを webui.bat の起動スクリプトである webui-user.bat で明示的に指定することができます。
webui-user.bat ファイルの「PYTHON」環境変数に、ご自身のPython インストールパスを指定してあげてください。
webui-user.bat 3行目
(変更前)set PYTHON=
↓
(変更後)set PYTHON=C:\Users\(ユーザ名)\AppData\Local\Programs\Python\Python310\python.exeもちろんこちらのパスは、「Python 3.10.6」の実行パスを指定することになります。
Python をインストールしている場所の調べ方
Windows の場合は、Pythonランチャー(py.exe)を利用してインストール場所を確認することができます。
py --list-paths複数インストールしている人は、以下のようにバージョンごとに表示されます。バージョン 3.10 のパスをコピーして利用します。
PS C:\Users\*****> py --list-paths
-V:3.11 * C:\Users\*****\AppData\Local\Programs\Python\Python311\python.exe
-V:3.10 C:\Users\*****\AppData\Local\Programs\Python\Python310\python.exe2. ローカル環境(GPU)が非力または、解像度が高い画像を作りたい人
わたしのように、GPUメモリが 足りない人は画像生成で 512 × 512 の画像を作成すると 100% メモリ不足のエラーが表示されます。
これを回避するために、少ないメモリでも画像生成を可能にする設定がいくつかあります。
これはアプリケーションの起動時のパラメタとなるため、いつでも変更が可能なものなので、以下のような GPU のメモリ不足エラーが表示されてから対応しても問題ないです。
OutOfMemoryError: CUDA out of memory. Tried to allocate 72.00 MiB (GPU 0; 4.00 GiB total capacity; 1.97 GiB already allocated; 59.05 MiB free; 2.08 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFwebui-user.bat 起動パラメタの指定
Stable Diffusion WebUI 本体起動用の webui.bat にパラメタ指定します。
具体的には、コマンドライン引数に「--xformers --medvram」パラメタを指定します。
(設定例)
set COMMANDLINE_ARGS=--xformers --medvram起動パラメタの説明
- xformers VRAMの使用量を軽減し画像生成を高速化するもの
- medvram 速度を犠牲にしてエラーとなるのを防ぐ(もしくは lowvram を利用)参考
- VRAM が 12GB 以上ある場合は不要です。
その他コマンドライン引数はこちらを参照してください。
Step3 起動ファイルを実行する
これまでの手順でアプリケーション起動の下準備はそろいました。
Stable Diffusion WebUI の起動
あとは、「webui-user.bat」を実行します。(インストールバッチ兼起動バッチとなっている)
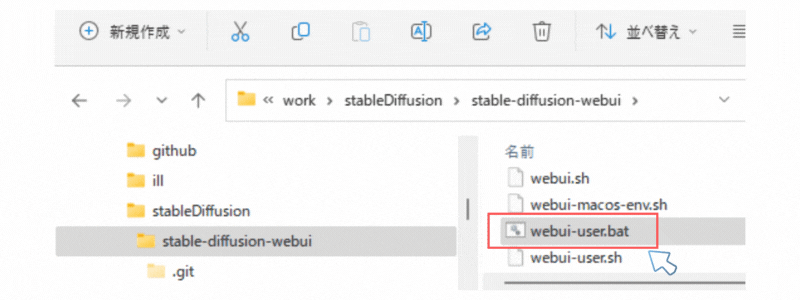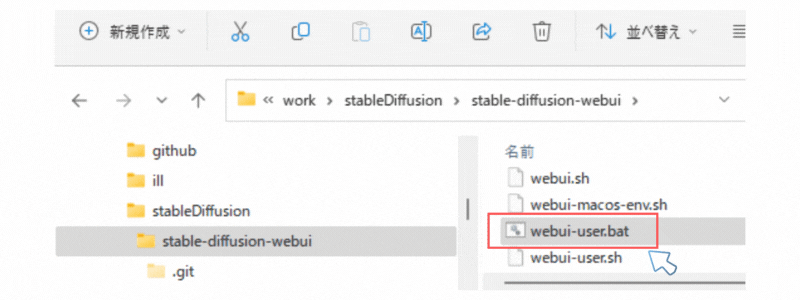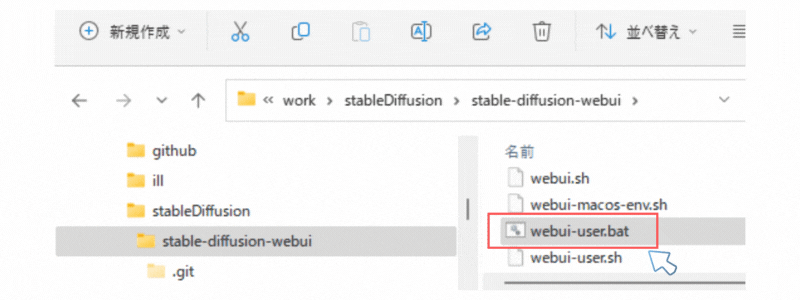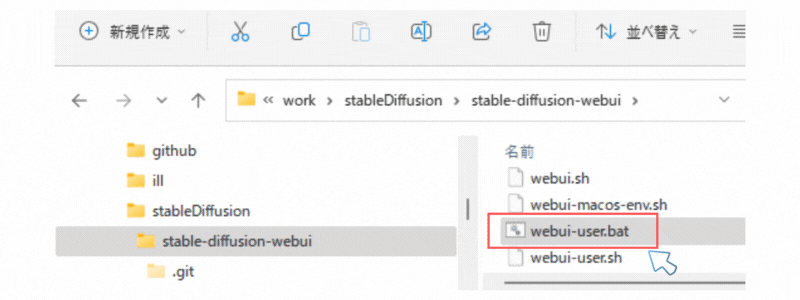
初回は、Python環境の構築や必要な資材(ライブラリ等)のダウンロードなどで時間がかかります。
エラーがなく終了したら、以下のような表示になり Stable Diffusion WebUI アクセス URL(http://127.0.0.1:7860) が表示されます。
「Ctrl」+クリックするか、対象URLをブラウザに張り付けてアクセスしてください。
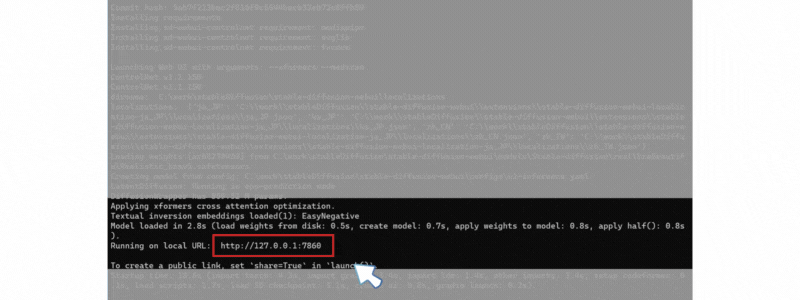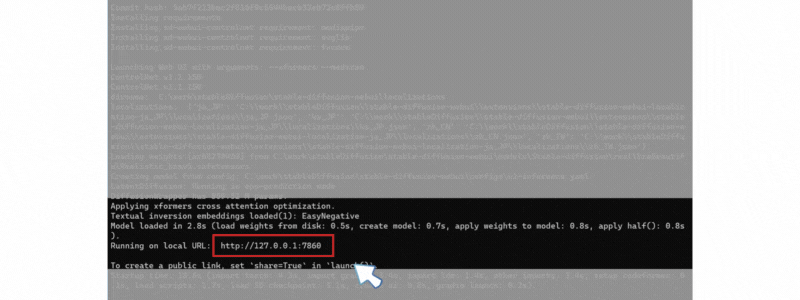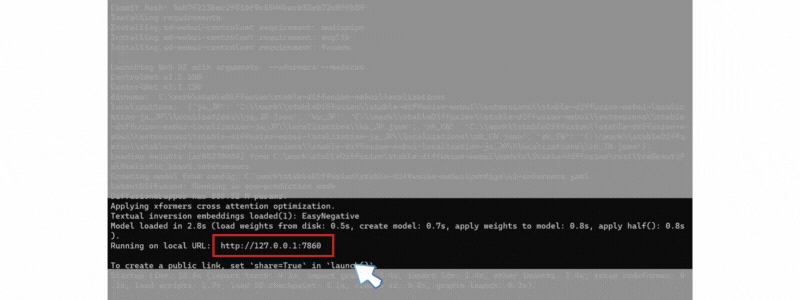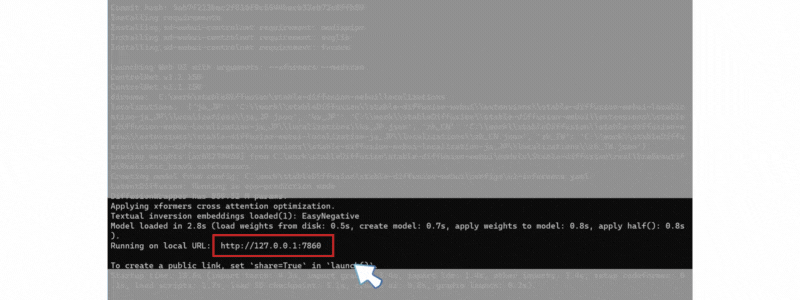
この コマンド画面は閉じないでください。
Stable Diffusion WebUI アクセス URL(http://127.0.0.1:7860)にアクセス
指定されたURLにアクセスすると、Stable Diffusion WebUI が表示されます。
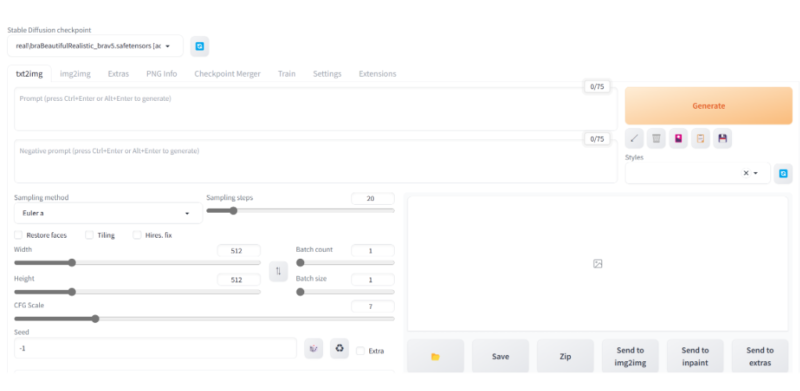
モデルデータのインストール
Stable Diffusion WebUI の画面表示できたら、あとは画像生成の心臓部であるモデルデータを用意します。
モデルデータは基本的に以下の2つのサイトからダウンロードして利用します。
今回は、今話題の写真で撮ったようなアジア人女性を生成できる BRA(BeautifulRealisticAsian の v5 を利用してみます。
インストールは簡単で、モデルをダウンロードして所定のフォルダに配置するだけです。
モデルデータをダウンロード
CIVITAI の BRA サイトにアクセスし、「Download」を押してモデルデータをダウンロードします。
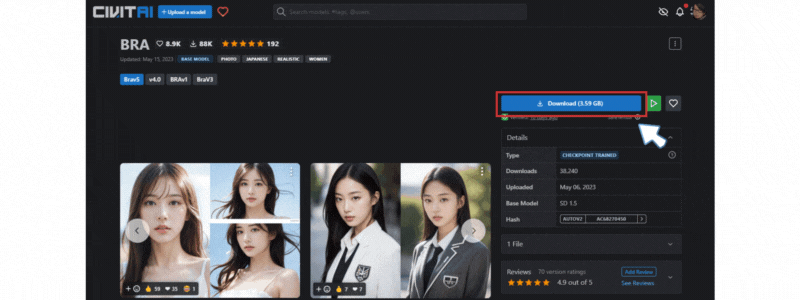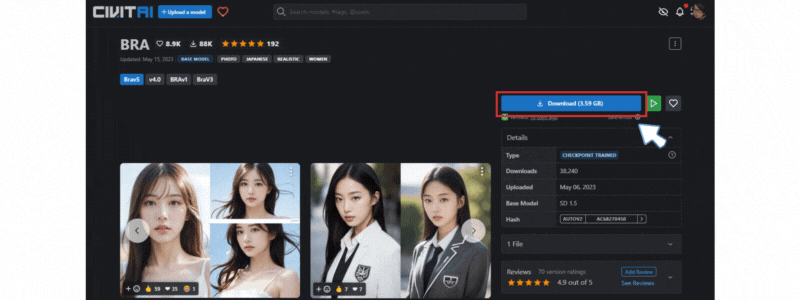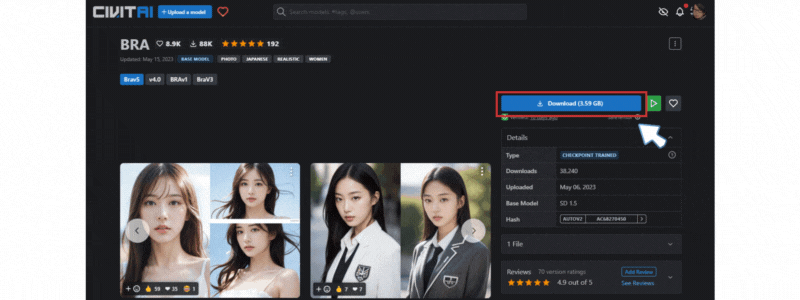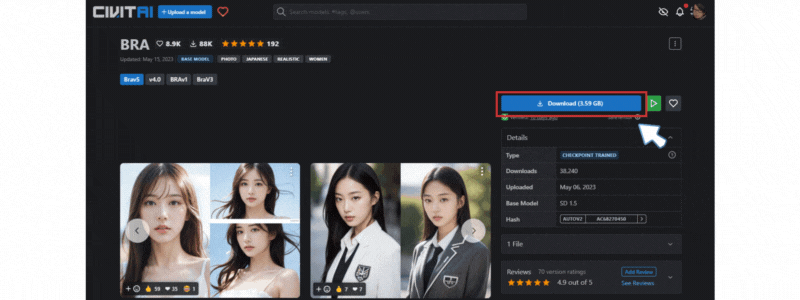
モデルデータを配置
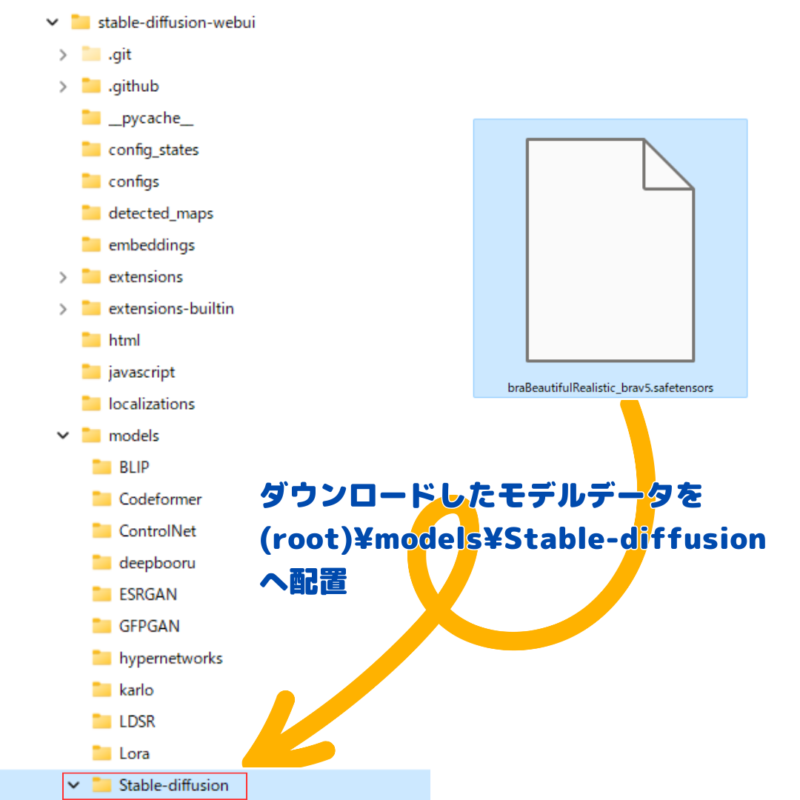
ダウンロードしたモデルデータは、ルートディレクトリ(インストールしたフォルダ)配下の
「models」> 「Stable-diffusion」
に配置します。
これでインストールは完了です。
モデルが多くなってきたら
モデル配置するフォルダ配下をフォルダで分類することができます。
たとえば、アニメ調なモデルとリアル調のモデルをフォルダ分けてしておくことで、プルダウンを選択する際にわかりやすくできます。
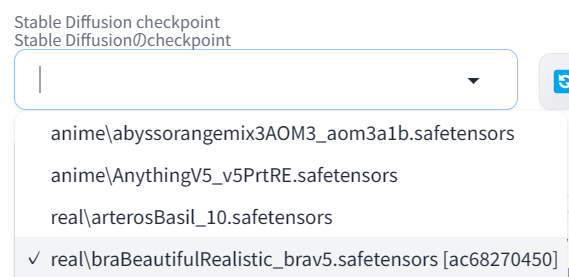
モデルを画面に反映
インストールされたモデルは Stable Diffusion WebUI の画面左上のプルダウンに表示されます。
表示されていない場合は、右のリロードアイコンをクリックすると表示されます。
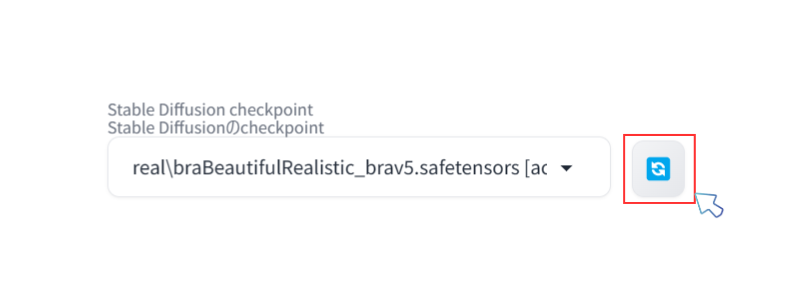
プルダウンを選択することで、画面にモデルが反映され画像生成の準備ができます。
画像を生成する
モデル開発者の解説を参考に、以下のプロンプトで画像生成してみます。
Stable Diffusion WebUI の画面で「txt2img」 タブを選択します。
基本やることは3つだけです。
- ポジティブプロンプト(AIに生成してもらいたい画像の指示)の入力
- ネガティブプロンプト(AIに生成時に行ってもらいたくない事柄)の入力
- その他設定パラメタの設定
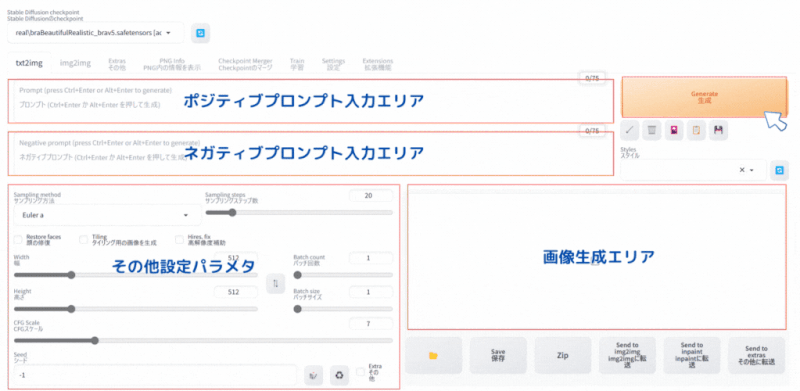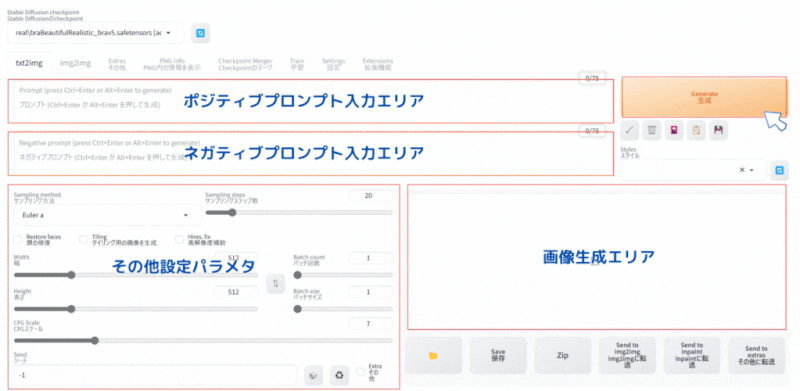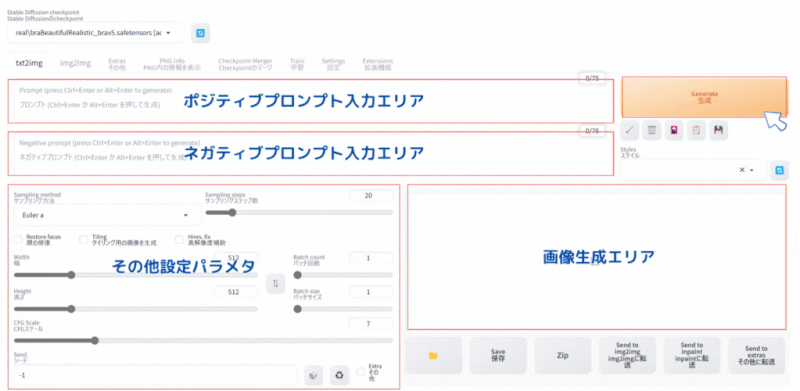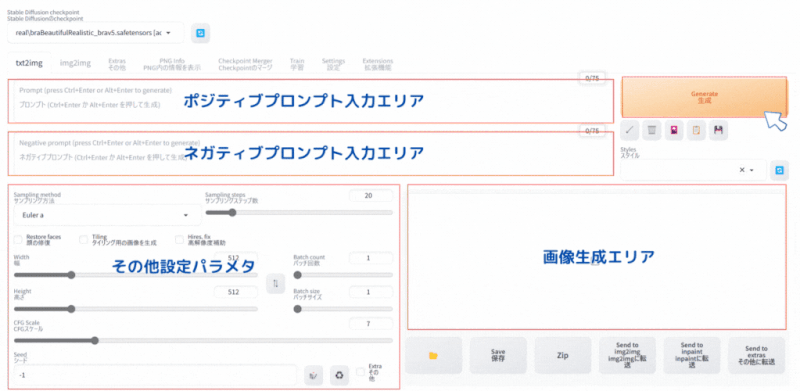
ポジティブプロンプト
(Best quality, 8k, 32k, Masterpiece, UHD:1.2),Photo of Pretty Japanese woman,
a woman with long hair and a black top is posing for a picture with her hand on her chin, 1girl, solo, long_hair, looking_at_viewer, brown_hair, simple_background, black_hair, jewelry, earrings, necklace, lips, black_shirt, ring, realisticネガティブプロンプト
(Worst Quality:2.0), multiple angle,blurry,longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality,text,error,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry,missing fingers,bad hands,missing arms,head_out_of_frame,2koma,panel layout,その他設定パラメタ
| パラメタ名 | 設定値 |
|---|---|
| Sampling method | DPM++ 2M Karras |
| Sampling steps | 25 |
| Width | 512 |
| Height | 512 |
| CFG Scale | 7 |
| Seed | -1 |
その他設定パラメタ
生成する画像の調整項目になります。
モデルや端末のスペックによって変更します。
| パラメタ名(EN) | 日本語(JA) | 説明 | 補足 |
|---|---|---|---|
| Sampling method | サンプリング方法 | 変更すると絵のスタイルが変わります。通常モデルごとに推奨する方法があるため、モデルのドキュメントを参照します。 | |
| Sampling steps | サンプリングステップ数 | 数値が多いほど画像への書き込みが増えます。 | 通常 20 ~ 60 がおすすめ。 |
| Restore faces | 顔の修復 | 出力画像をGFPGANで顔補正します。 | デフォルト OFF |
| Tiling | タイリング用の画像を生成 | 出力画像をタイルのように並べます。 | デフォルト OFF |
| Hires. fix | 高解像度補助 | 高解像度出力するための機能の有効化ができます。 | デフォルト OFF |
| Width | 幅 | 画像の横解像度(サイズ) | デフォルト 512 |
| Height | 高さ | 画像の縦解像度(サイズ) | デフォルト 512 |
| Batch count | バッチ回数 | バッチを生成する回数 | デフォルト 1 |
| Batch size | バッチサイズ | 1回に生成する枚数 | デフォルト 1 |
| CFG Scale | CFGスケール | 数値が小さいと品質が向上するが、プロンプトへの忠実度が下がります。 | 7 ~ 11 がおすすめ。 |
| Seed | シード | 画像生成のバリエーションを表現しています。数値を固定すると同条件で再生成しても同じ画像が表示されます。 | -1 ランダム |




いかがでしょうか、写真のような画像が生成されました。
プロンプトの単語を変更することでさまざまな画像を生み出すことができます。
しかもモデルごとのライセンスを守ったうえであれば、商用利用可能な場合が多いので、広告などの表現の場でいろいろな使い道があると思います。
商用利用する上でライセンスは確認すること
実際には商用利用する際は、モデルのライセンスを確認してください。基本は対象モデルのライセンスを確認すればよいですが、モデルによっては派生モデルや合成モデルといって大本のモデルのライセンスを引き継いでいるものもあります。特に注意書きがない場合は、大本のライセンスを確認することになります。
また、商用利用可であっても使用制限などが記載されている場合が多いです。基本は法令順守や公序良俗に反する行為は禁止の類だと思いますが、学習データに準じた禁止事項も想定されるため、確認することをお勧めします。特に著作権侵害などは知らないうちに起こしてしまう危険があります。

おすすめの拡張機能
画面項目の日本語化
日本語化は賛否がわかれるところですが。
日本語のほうが直感的に機能がわかりやすくなる人は大多数います。
機能のオンオフが簡単にできるのでインストールをお勧めします。
また、バイリンガル機能といって多少画面が煩雑になりますが、両方の言語を表示することもできます。
画面項目の日本語化方法はこちら

まとめ
いかがでしたでしょうか。
これで、画像生成を思う存分できる準備が整いました。あとはお気に入りのモデルや拡張機能を試しながら、Try & Error で試してみてください。
- Stable Diffusion WebUI を利用してローカルで画像生成ができるようになった。
- 生成時に必要なパラメタの存在を把握して、生成における基本的な操作がわかるようになった。
- 拡張機能のインストールの仕方がわかり設定が簡単に行えることがわかった。
最後にもう一度確認



{kind=link}